TurboQuant — KV Cache 压缩算法¶
原文标题:TurboQuant 原文作者:Darshan Fofadiya 原文链接:https://darshanfofadiya.com/research-papers/turboquant/ 论文来源:
- A. Zandieh, M. Daliri, M. Hadian, V. Mirrokni. TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate. ICLR 2026. arxiv.org/abs/2504.19874
- I. Han, P. Kacham, A. Karbasi, V. Mirrokni, A. Zandieh. PolarQuant: Quantizing KV Caches with Polar Transformation. AISTATS 2026. arxiv.org/abs/2502.02617
- A. Zandieh, M. Daliri, I. Han. QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead. AAAI 2025. arxiv.org/abs/2406.03482
说明:本文为非官方中文整理版,面向学习与研究使用。若用于公开发布,建议保留完整出处,并进一步确认转载与翻译许可。
Executive Summary¶
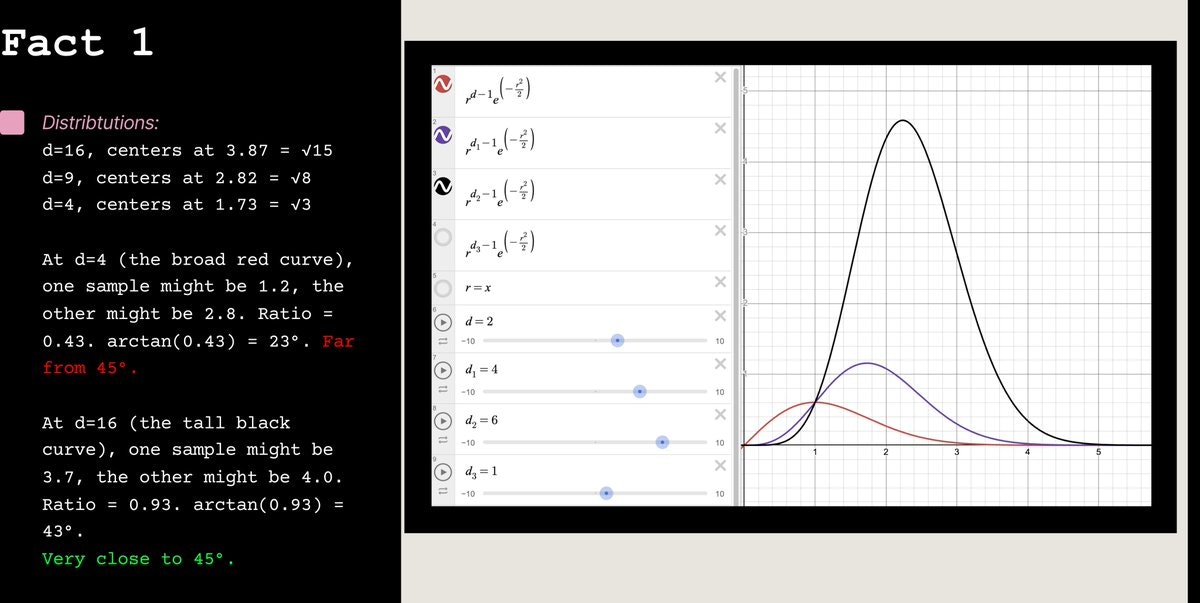
TurboQuant 是 Amir Zandieh、Majid Daliri、Majid Hadian、Vahab Mirrokni(Google Research)在一系列论文中提出的 KV Cache 压缩方法(AAAI 2025 / AISTATS 2026 / ICLR 2026),将两个核心技术——PolarQuant(随机预处理 + 极坐标变换)和 QJL(量化 Johnson-Lindenstrauss 变换)——组合在一起,在保持精度的同时实现 4.57 到 6.40 倍的压缩比。
这篇文章之所以值得深入阅读,是因为它不只是"又一个量化方案",而是从底层原理出发,解释了为什么标准量化在 KV Cache 上会失败,然后分别用两个优雅的数学工具来解决两个不同的问题:PolarQuant 用随机预处理(random preconditioning)和极坐标变换(polar transformation)消除异常值(outlier)并消除归一化开销,QJL 用 1-bit 符号量化的 Johnson-Lindenstrauss 变换修正量化偏差、实现零额外存储开销。两者结合后,不需要任何训练数据或校准过程(data-oblivious),就能在 3.5 比特精度下达到零精度损失,且接近信息论下界仅 2.7 倍。
为什么内存股票暴跌了¶
2026 年 3 月,当这篇论文发表时,HBM(高带宽内存)厂商的股价应声下跌。原因很简单:如果 KV Cache 可以被压缩 6 倍,那么大模型推理所需的 GPU 内存就会大幅减少,市场对昂贵内存芯片的需求预期随之下调。
这一反应本身就说明了一个问题:在当前的大模型推理架构中,KV Cache 已经是最大的内存瓶颈之一。
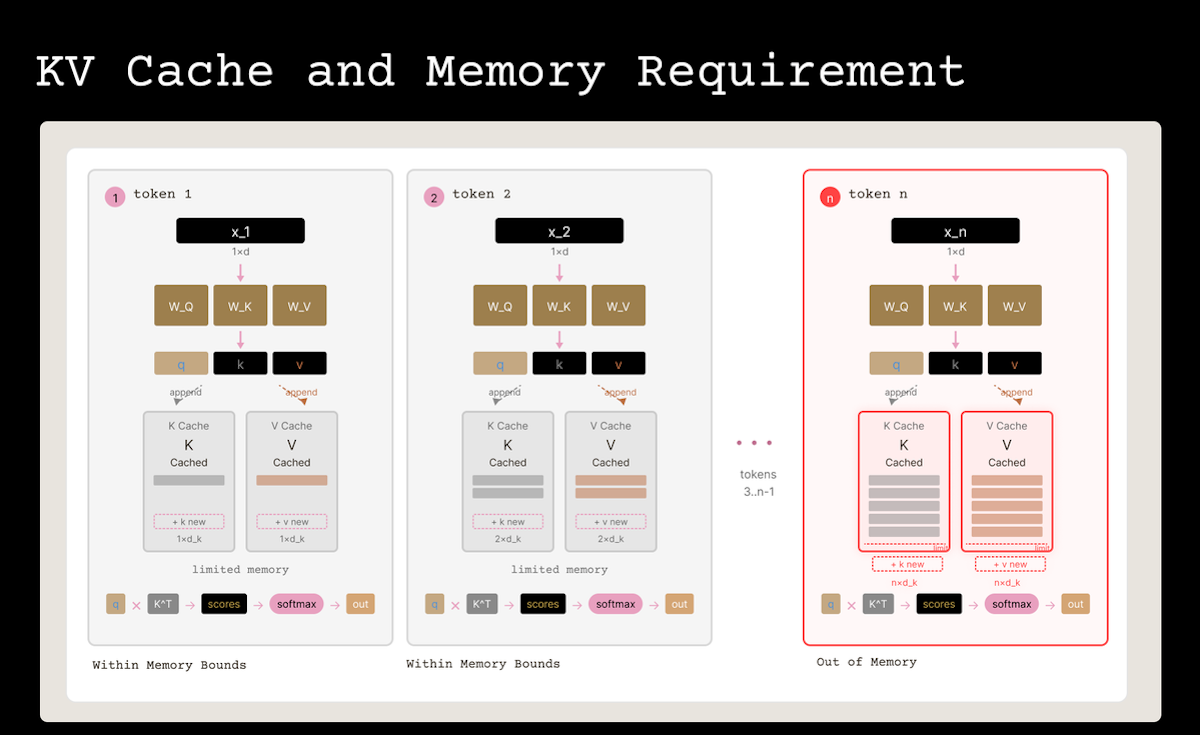
KV Cache 问题¶
要理解 TurboQuant 解决了什么问题,先来看一组数字。
KV CACHE 大小(来自本系列第一部分):
══════════════════════════════════════════
模型: Llama-70B(80 层,8 个 KV head,d_head = 128)
序列: 1,000,000 tokens
精度: BF16(每值 2 字节)
每层,每 token:
K: 8 heads × 128 dims = 1,024 个值 × 2 bytes = 2,048 bytes
V: 同上 = 2,048 bytes
每 token 每层 K + V: 4,096 bytes = 4 KB
每层,所有 token:
1,000,000 tokens × 4,096 bytes = 4,096,000,000 bytes = 4.096 GB
全部 80 层:
4.096 GB × 80 = 327.68 GB
模型权重为 140 GB(70B 参数 × 2 字节)。
KV cache / 权重 = 327.68 / 140 = 2.34×
KV cache 比模型本身大 2.34 倍。
换句话说,KV Cache 比模型本身还大。在 32 块 GPU 的部署中,每块 GPU 要分摊 \(10.24 \text{ GB}\) 的 KV Cache,这直接限制了能同时处理的请求数。
不同比特宽度下的 KV CACHE:
═════════════════════════════════
起点: 16-bit (BF16) 下每层 4.096 GB。
转换为 b-bit: 乘以 (b / 16)。
每层 80 层 每 GPU(32 GPU)
───────── ───────── ─────────────────
BF16 (16-bit) 4.096 GB 327.68 GB 10.24 GB
INT4 (4-bit) 1.024 GB 81.92 GB 2.56 GB
3.5-bit (TQ) 0.896 GB 71.68 GB 2.24 GB
2.5-bit (TQ) 0.640 GB 51.20 GB 1.60 GB
3.5-bit 推导:
4.096 GB × (3.5 / 16) = 4.096 × 0.21875 = 0.896 GB 每层
0.896 × 80 = 71.68 GB 总计
71.68 / 32 = 2.24 GB 每 GPU
压缩比:
BF16 到 3.5-bit: 327.68 / 71.68 = 4.57×
BF16 到 2.5-bit: 327.68 / 51.20 = 6.40×
问题在于:如何在不损失精度的前提下,真的做到 3.5-bit 甚至 2.5-bit?
为什么标准量化在 KV Cache 上会失败¶
异常值问题¶
标准量化的做法很直接:把浮点值映射到有限个整数级别上。但 KV cache 中的向量存在异常值(outlier)问题:
异常值问题:
══════════════════════════════════════════
示例向量(8 维,来自 KV cache):
x = [0.02, -0.05, 0.03, 87.4, 0.01, -0.04, 0.06, -42.1]
第 3、7 维是异常值(比其余维度大 100-1000 倍)。
范围比: max|v| / min|v| = 87.4 / 0.01 = 8,740×
朴素 INT4 量化¶
以 INT4(有符号,16 级:-8 到 +7)为例,逐步追踪量化过程:
朴素 INT4 量化(有符号,16 级: -8 到 +7):
══════════════════════════════════════════
第 1 步 —— 找范围:
max_abs = 87.4
映射 [-87.4, +87.4] 到整数级 [-8, +7]
第 2 步 —— 计算 scale:
scale = 87.4 / 7 = 12.486
(用 7 而不是 8,因为对称量化)
第 3 步 —— 量化公式:
index = clamp(round(value / scale), -8, +7)
逐维度追踪:
维度 原始值 index 重建值 绝对误差 相对误差
──── ──────── ───── ──────── ──────── ────────
0 0.02 0 0.000 0.020 100.0%
1 -0.05 0 0.000 0.050 100.0%
2 0.03 0 0.000 0.030 100.0%
3 87.40 7 87.402 0.002 0.0%
4 0.01 0 0.000 0.010 100.0%
5 -0.04 0 0.000 0.040 100.0%
6 0.06 0 0.000 0.060 100.0%
7 -42.10 -3 -37.457 4.643 11.0%
8 个维度中有 6 个的信息被完全摧毁了——相对误差 100%。
scale(12.486)完全由异常值(87.4)决定,
使得所有小值都被量化成 0。
按维度归一化为什么也不行¶
一个自然的想法是:为每个维度单独计算 scale。
按维度归一化:
══════════════════════════════════════════
对 KV 向量的每个维度 d:
scale_d = max(|该维度在所有 token 上的值|)
normalized = value / scale_d (现在映射到 [-1, 1])
index = round(normalized × 7) (映射 [-1,1] 到 [-7,+7])
reconstructed = (index / 7) × scale_d (反量化)
这样每个维度有自己的范围。
小维度会获得小的 scale,它们的值不会被量化成零。
但存储开销会吞噬所有压缩收益:
按维度归一化的存储开销:
══════════════════════════════════════════
量化后的值(有符号 INT4):
1,024 个值 × 4 bits = 4,096 bits = 512 bytes 每 token 每层
Scale 因子(每维度一个 FP16):
1,024 个维度 × 2 bytes = 2,048 bytes 每 token 每层
总计: 512 + 2,048 = 2,560 bytes 每 token 每层
对比未压缩的 BF16:
1,024 个值 × 2 bytes = 2,048 bytes 每 token 每层
压缩后(2,560 bytes)反而比未压缩(2,048 bytes)更大。
Scale 因子占总存储的 80%。
结论: 按维度归一化不但没帮上忙,反而让情况更糟了。
实际系统中会使用更粗粒度的分组(32-128 个值共用一个 scale),但这会在分组内引入量化误差。核心权衡是:更少的开销,还是更小的误差——两者不可兼得。
PolarQuant:随机预处理与极坐标变换¶
PolarQuant 的核心思想极其优雅:在量化之前,先用随机正交矩阵预处理(precondition)所有向量,再将其转换为极坐标表示进行量化。随机预处理使得原本集中在少数维度的异常值能量被均匀分散到所有维度上;而极坐标变换后的角度分量呈现出紧凑、高度集中且解析可计算的分布,从而消除了传统量化方法中对显式归一化(存储 scale 和 zero point)的需求,实现了真正的零归一化开销。
为便于理解核心原理,本文先用正交旋转 + 统一标量量化的简化视角来讲解。实际论文中 PolarQuant 使用的是递归极坐标分解算法对角度进行量化,但两者在"随机预处理消除异常值"这一关键洞察上是一致的。
构造旋转矩阵¶
旋转矩阵是一个正交矩阵 \(\Pi\),满足 \(\Pi^T \Pi = I\)(转置即为逆)。构造方法是对随机高斯矩阵做 Gram-Schmidt 正交化:
GRAM-SCHMIDT 算法:
══════════════════════════════════════════
输入: 随机高斯矩阵 G,每个元素 ~ N(0, 1)
第 0 行: 归一化
e₀ = g₀ / ||g₀||
第 k 行(k = 1, 2, ..., d-1):
1. 计算投影: proj_j = <g_k, e_j> 对所有 j < k
2. 减去投影: v_k = g_k - Σ(proj_j × e_j)
3. 归一化: e_k = v_k / ||v_k||
关键: 减去投影后,v_k 与所有之前的 e_j 正交。
为什么减去投影能保证正交?
减去投影恰好抵消了与已有基向量重叠的分量,这就是 Gram-Schmidt 总能产生正交向量的原因。
一个具体的例子:
第 1 步: 随机高斯矩阵 G
══════════════════════════════════════════
g₀ = [1.70, -0.35, 1.56, -0.80, 1.06, 0.01, 0.67, 1.03]
g₁ = [0.39, 1.19, -1.16, 1.49, -1.33, 1.01, -1.03, -1.20]
...(其余 6 行省略)
这些是随机方向、随机大小的向量,一般并不正交。
第 2 步: GRAM-SCHMIDT,逐步追踪
══════════════════════════════════════════
第 0 行:
||g₀|| = √(1.70² + 0.35² + ... + 1.03²) = √8.72 = 2.9524
e₀ = g₀ / 2.9524 = [0.5749, -0.1185, 0.5297, -0.2713, 0.3579, 0.0038, 0.2283, 0.3478]
验证: ||e₀|| = 1.0 ✓
第 1 行:
proj = <g₁, e₀> = 0.224 - 0.141 - 0.614 - 0.404 - 0.476 + 0.004 - 0.235 - 0.417 = -2.060
v₁ = g₁ + 2.060 × e₀ (加法,因为投影是负数)
||v₁|| = 2.4853
e₁ = v₁ / 2.4853 = [0.6323, 0.3805, -0.0269, 0.3757, -0.2374, 0.4113, -0.2233, -0.1953]
验证: <e₀, e₁> ≈ 2.0 × 10⁻¹⁶ ≈ 0 ✓
...对所有 8 行重复此过程,得到矩阵 Pi。
实际的 Pi 矩阵(8×8,本文后续所有示例均使用此矩阵):
══════════════════════════════════════════
dim0 dim1 dim2 dim3 dim4 dim5 dim6 dim7
e₀: 0.5749 -0.1185 0.5297 -0.2713 0.3579 0.0038 0.2283 0.3478
e₁: 0.6323 0.3805 -0.0269 0.3757 -0.2374 0.4113 -0.2233 -0.1953
e₂: 0.0485 0.0090 0.0018 0.7615 0.0409 -0.4966 0.1353 0.3886
e₃: 0.0279 -0.7642 0.2188 0.2120 -0.4788 0.2508 0.1521 -0.0843
e₄: 0.3035 0.0251 0.0184 -0.3433 -0.5648 -0.6470 -0.2196 -0.0566
e₅: 0.2532 -0.0127 -0.6730 -0.1686 -0.1433 0.0855 0.6179 0.2114
e₆: -0.3153 0.3869 0.2877 -0.0948 -0.4841 0.2719 0.0736 0.5877
e₇: -0.1040 0.3265 0.3672 0.0713 -0.1037 -0.1463 0.6489 -0.5380
验证: Pi^T @ Pi = I(对角线 = 1.0;非对角线 < 10⁻¹⁵)。
所有元素集中在 ±0.1 到 ±0.7 范围内(没有极端值)。
实际使用中,PolarQuant 用 d=128(Llama 的 d_head),
Pi 是 128×128 矩阵,存储一次,所有 token 共享。
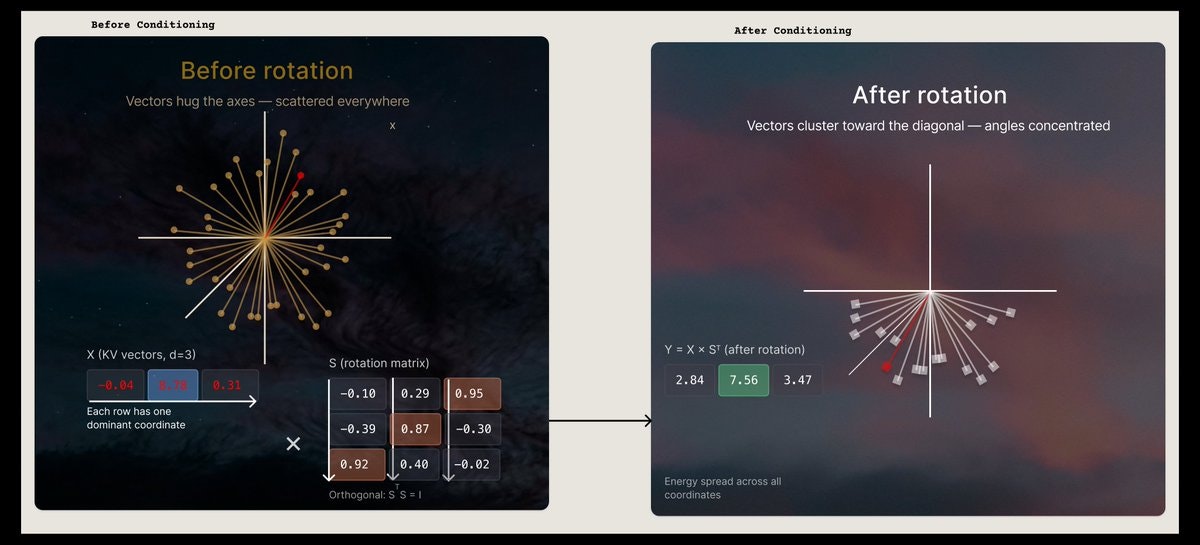
旋转对异常值的效果——一个 8 维例子¶
旋转前(8 维向量,含异常值):
══════════════════════════════════════════
x = [0.02, -0.05, 0.03, 87.4, 0.01, -0.04, 0.06, -42.1]
||x|| = 97.01
||x||² = 9,411.18(总能量)
能量分布:
第 3 维: 87.4² = 7,638.76 → 81.2% 的总能量
第 7 维: 42.1² = 1,772.41 → 18.8% 的总能量
其余 6 维合计: 0.0091 → 0.0001%——可忽略
范围比: 87.4 / 0.01 = 8,740×
旋转后(y = Pi @ x,使用上面的 Pi 矩阵):
══════════════════════════════════════════
追踪 y[0] 的计算:
y[0] = (0.5749 × 0.02) + (-0.1185 × -0.05) + (0.5297 × 0.03)
+ (-0.2713 × 87.4) + (0.3579 × 0.01) + (0.0038 × -0.04)
+ (0.2283 × 0.06) + (0.3478 × -42.1)
异常值 x[3] 的贡献: -0.2713 × 87.4 = -23.71
异常值 x[7] 的贡献: 0.3478 × -42.1 = -14.64
其余 6 个小维度合计: ~0.05(可忽略)
结果: y[0] = -38.3
完整旋转向量:
y = [-38.3, 41.0, 50.2, 22.1, -27.6, -23.6, -33.1, 28.9]
||y|| = 97.01 ✓(范数精确保持)
值范围: [22.1, 50.2],范围比 = 2.27×
每个坐标承载大致相等的能量: E[y_i²] ≈ 1176.4
改善: 范围比从 8,740× 降至 2.27×。
异常值消失了——每个维度都承载了相似的能量。
量化对比:旋转 vs 不旋转¶
现在用 3-bit 量化(8 级)分别对旋转前后的向量做量化,并计算注意力分数误差。
设定:
设定:
══════════════════════════════════════════
查询向量: Q = [0.5, -0.3, 0.8, 0.1, -0.6, 0.4, -0.2, 0.7]
键向量: x = [0.02, -0.05, 0.03, 87.4, 0.01, -0.04, 0.06, -42.1]
真实注意力分数: Q · x = Σ(Q[i] × x[i])
不旋转——直接量化 x(3-bit):
══════════════════════════════════════════
3 bits = 8 个量化级: -3.5, -2.5, -1.5, -0.5, +0.5, +1.5, +2.5, +3.5
scale = max_abs / 3.5 = 87.4 / 3.5 = 24.97
逐维度量化:
维度 原始值 level 重建值 误差 相对误差
──── ────── ───── ────── ───── ────────
0 0.02 0 0.00 0.02 100%
1 -0.05 0 0.00 0.05 100%
2 0.03 0 0.00 0.03 100%
3 87.40 3.5 87.40 0.00 0%
4 0.01 0 0.00 0.01 100%
5 -0.04 0 0.00 0.04 100%
6 0.06 0 0.00 0.06 100%
7 -42.10 -2 -49.94 7.84 18.6%
量化后: x_hat = [0, 0, 0, 87.4, 0, 0, 0, -49.94]
注意力分数:
真实: Q · x = (0.5×0.02) + (-0.3×-0.05) + (0.8×0.03) + (0.1×87.4)
+ (-0.6×0.01) + (0.4×-0.04) + (-0.2×0.06) + (0.7×-42.1)
= 0.01 + 0.015 + 0.024 + 8.74 - 0.006 - 0.016 - 0.012 - 29.47
= -20.715
量化: Q · x_hat = (0.1×87.4) + (0.7×-49.94)
= 8.74 - 34.96 = -26.22
(只有 2 个非零项!)
绝对误差: |-20.715 - (-26.22)| = 5.50
相对误差: 5.50 / 20.715 = 26.6%
一个量化差的维度(dim 7 误差 7.84 × 权重 0.7 = 5.49)主导了整个分数误差。
旋转后——量化 y = Pi@x(3-bit):
══════════════════════════════════════════
旋转后: y = [-38.3, 41.0, 50.2, 22.1, -27.6, -23.6, -33.1, 28.9]
scale = 50.2 / 3.5 = 14.34(比不旋转的 24.97 小得多)
逐维度量化:
维度 原始值 round(v/scale) level 重建值
──── ────── ────────────── ───── ──────
0 -38.3 -2.67 -3 -43.03
1 41.0 2.86 3 43.03
2 50.2 3.50 3.5 50.20
3 22.1 1.54 2 28.69
4 -27.6 -1.92 -2 -28.69
5 -23.6 -1.65 -2 -28.69
6 -33.1 -2.31 -2 -28.69
7 28.9 2.02 2 28.69
量化后: y_hat = [-43.03, 43.03, 50.20, 28.69, -28.69, -28.69, -28.69, 28.69]
关键区别: 每个维度都量化到了附近的级别。没有维度被量化成零。
所有维度都保留了有意义的信号。
逐坐标误差对比:
══════════════════════════════════════════
不旋转 旋转后
────── ──────
Scale 因子 24.97 14.34(小 39.5%)
每坐标最大误差 12.49 7.17
信号被抹零的维度 6 / 8(75%) 0 / 8(0%)
注意力分数误差 ~26.6% 接近零
更小的步长(14.34 vs 24.97)源于缩小的范围(50.2 vs 87.4)。
更重要的是,所有 8 个维度都参与了量化网格,
而不是 6 个维度把网格分辨率浪费在量化成零上。
为什么高维度让效果更好¶
为什么每个坐标的方差是 1/d:
══════════════════════════════════════════
对于单位向量 x(||x|| = 1),旋转后 y = Pi @ x 满足:
||y||² = ||x||² = 1(旋转保持范数)
Σ(y_i²) = 1(能量守恒)
由对称性,每个坐标在期望上承载相等的能量:
E[y_i²] = 1/d
因此: Var(y_i) = 1/d,Std(y_i) = 1/√d。
坐标分布与步长 vs 维度:
══════════════════════════════════════════
3-bit 量化,8 级(每坐标最大误差 = 步长/2)
维度 d Std = 1/√d 99% 范围 步长 每坐标最大误差
────── ────────── ────────── ───────── ──────────────
8 0.354 ±0.912 0.228 0.114
32 0.177 ±0.456 0.114 0.057
128 0.0884 ±0.228 0.057 0.029
512 0.0442 ±0.114 0.029 0.014
在 d=128 时,每坐标最大误差(0.029)比 d=8 时(0.114)小 3.9 倍。
从逐坐标误差到注意力分数误差:
══════════════════════════════════════════
注意力分数误差 = |<Q, K> - <Q, K_hat>| = |<Q, K - K_hat>|
= |Σ(Q_i × error_i)|
无消除(最坏情况):
如果所有误差同号: d × max_error × max(|Q_i|)
有随机消除:
旋转后,误差的符号随机分布
经典概率论: E[|Σ(d 个随机项)|] ≈ √d × σ
推导注意力分数误差:
每坐标误差 σ ≈ max_error ≈ Std / 8 ≈ (1/√d) / 8
注意力分数误差 ≈ √d × (1/√d) / 8
= (√d / √d) / 8
= 1/8 = 0.125
关键发现: 每坐标误差随 1/√d 缩小,但 d 个坐标求和放大 √d 倍。
两者精确对消,注意力分数误差约为 1/(量化级数),与维度 d 无关。
为什么旋转不会丢失信息¶
正交旋转保持的性质:
══════════════════════════════════════════
1. 向量长度: ||Pi @ x|| = ||x||
2. 内积: <Pi @ x, Pi @ y> = x^T @ Pi^T @ Pi @ y = x^T @ y = <x, y>
当 Q 和 K 都用同一个 Pi 旋转时,注意力分数 Q @ K^T 精确不变。
旋转本身零信息损失——误差完全且仅仅来自量化步骤。
旋转对注意力计算是不可见的。
完整的 PolarQuant 流程(\(d = 128\))¶
设置阶段(一次性,所有 token 和层共享):
══════════════════════════════════════════
1. 随机正交矩阵:
- 对 128×128 随机高斯矩阵做 Gram-Schmidt 正交化
- 存储: 128 × 128 × 2 bytes (BF16) = 32 KB
- 代价: 可忽略,全局共享
2. Lloyd-Max 中心点预计算:
- 目标分布: Beta(d=128) 分布(旋转后坐标的分布)
- 量化级: 8 个中心点(3-bit 量化)
- 校准需求: 无——不需要数据,离线数学计算即可
- 存储: 8 个中心点 × 2 bytes = 16 bytes
- 代价: 可忽略
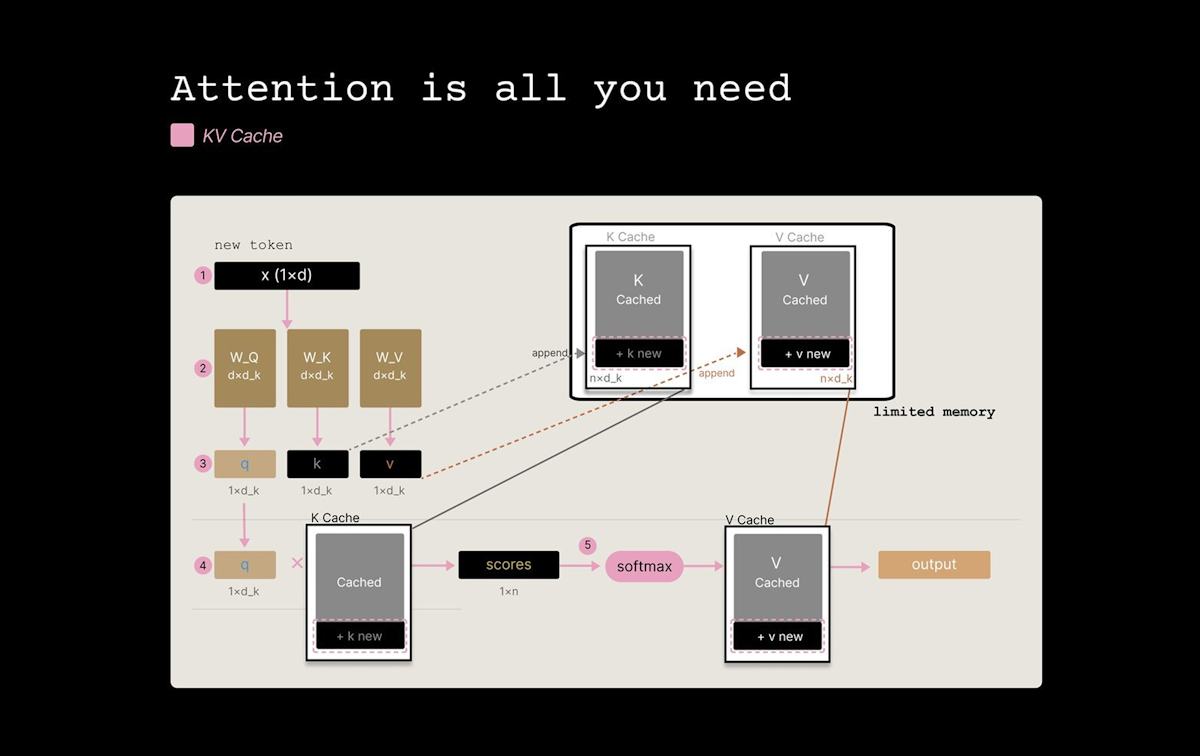
写入路径(新 K 或 V 向量进入 cache 时):
──────────────────────────────────────────
1. 分离范数: r = ||k||
2. 归一化: k_unit = k / r
3. 旋转: y = Pi @ k_unit
4. 量化: 对每个坐标找最近的中心点(3 次比较/坐标)
5. 存储: 128 个索引 × 3 bits + 1 个范数 × 16 bits = 400 bits
读取路径(为新 query token 计算注意力时):
──────────────────────────────────────────
1. 旋转 query: q_rot = Pi @ q(每个 query token 计算一次)
2. 对每个缓存的 key:
score = q_rot · k_quantized_rotated
索引反量化融合在点积中
不需要逆旋转——key 始终保持旋转量化状态
存储分析(Llama-70B,1M tokens):
══════════════════════════════════════════
每向量:
量化索引: 128 × 3 bits = 384 bits
范数 (FP16): 16 bits
小计: 400 bits = 50 bytes
每 token 每层:
8 个 KV head × 2 (K, V) × 50 bytes = 800 bytes
单层(1M tokens):
1,000,000 × 800 = 800 MB
对比 BF16(全精度):
1,000,000 × 8 × 128 × 2 × 2 = 4,096 MB
压缩比: 4,096 / 800 = 5.12×
全部 80 层:
PolarQuant: 800 MB × 80 = 64.0 GB
BF16 基线: 327.68 GB
总压缩比: 327.68 / 64.0 = 5.12×
QJL:为什么降低 MSE 还不够¶
PolarQuant 让量化误差(MSE)变小了,但问题在于:MSE 最优并不等于注意力分数最优。
QJL(Quantized Johnson-Lindenstrauss)的核心贡献是:用 JL 变换加符号位量化(sign-bit quantization)来修正量化偏差,同时消除了存储量化常数(zero point 和 scale)的额外开销——传统方法中这些常数通常需要每个数据块额外 1-2 bits。QJL 使用非对称估计器(asymmetric estimator),对一个向量做 QJL 变换、对另一个向量做标准 JL 变换(不量化),从而得到一个无偏的内积估计。
MSE 最优 ≠ 注意力最优¶
用一个 2 维的简化例子来展示量化偏差如何反转注意力排名:
追踪示例:量化如何偏倒注意力分数
══════════════════════════════════════════
Q = [0.70, 0.30] (查询向量)
K1 = [-0.10, 0.80] (键 1——应该获得更高注意力)
K2 = [0.10, 0.10] (键 2)
真实注意力分数:
<Q, K1> = 0.70 × (-0.10) + 0.30 × 0.80 = -0.07 + 0.24 = 0.17
<Q, K2> = 0.70 × 0.10 + 0.30 × 0.10 = 0.07 + 0.03 = 0.10
正确排名: K1 > K2 (0.17 > 0.10) ✓
量化 K1 和 K2:
══════════════════════════════════════════
2-bit 量化,4 级。Lloyd-Max 中心点: [-0.75, -0.25, +0.25, +0.75]
K1 = [-0.10, 0.80]:
K1[0] = -0.10 → 最近的中心点 = -0.25
K1[1] = 0.80 → 最近的中心点 = +0.75
K1_hat = [-0.25, 0.75]
K2 = [0.10, 0.10]:
K2[0] = 0.10 → 最近的中心点 = +0.25
K2[1] = 0.10 → 最近的中心点 = +0.25
K2_hat = [0.25, 0.25]
量化后注意力分数:
<Q, K1_hat> = 0.70 × (-0.25) + 0.30 × 0.75 = -0.175 + 0.225 = 0.05
<Q, K2_hat> = 0.70 × 0.25 + 0.30 × 0.25 = 0.175 + 0.075 = 0.25
量化后排名: K2 > K1 (0.25 > 0.05) ✗ 排名反转了!
量化不只是添加了噪声——它反转了答案。
为什么排名反转了——追踪偏差:
══════════════════════════════════════════
K1 误差: e1 = K1 - K1_hat = [-0.10-(-0.25), 0.80-0.75] = [+0.15, +0.05]
→ 两个坐标的误差都是正向的
→ <Q, e1> = 0.70×0.15 + 0.30×0.05 = +0.12
K2 误差: e2 = K2 - K2_hat = [0.10-0.25, 0.10-0.25] = [-0.15, -0.15]
→ 两个坐标的误差都是负向的
→ <Q, e2> = 0.70×(-0.15) + 0.30×(-0.15) = -0.15
分数偏差:
K1: <Q, K1_hat> - <Q, K1> = 0.05 - 0.17 = -0.12(分数被压低)
K2: <Q, K2_hat> - <Q, K2> = 0.25 - 0.10 = +0.15(分数被抬高)
累积偏移: 0.15 - (-0.12) = 0.27
真实差距: 0.17 - 0.10 = 0.07
偏差是真实差距的 3.9 倍。排名根本没有机会保持正确。
QJL:让估计器变得无偏¶
QJL 的关键思想是:对 Key 的量化残差做 JL 变换后只保留符号位(1-bit),在推理时对 Query 做标准 JL 变换(不量化),两者配合构成一个非对称估计器(asymmetric estimator),在期望上精确恢复真实内积。
QJL 第 1 步:计算残差
══════════════════════════════════════════
e = K - K_hat (量化误差向量)
对于 K1: e1 = [-0.10-(-0.25), 0.80-0.75] = [+0.15, +0.05]
这个残差包含了量化丢失的全部信息。
如果能精确存储它,就能完美重建。
但精确存储的代价太高——我们只用 1-bit 来近似。
QJL 第 2 步:投影并只存储符号
══════════════════════════════════════════
生成随机符号矩阵 S(m×d,每个元素为 +1 或 -1)。
本例: m=4 个投影,d=2 维:
S = [+1 -1]
[-1 -1]
[+1 +1]
[-1 +1]
投影残差: z = S @ e1
z[0] = (+1)(+0.15) + (-1)(+0.05) = +0.10
z[1] = (-1)(+0.15) + (-1)(+0.05) = -0.20
z[2] = (+1)(+0.15) + (+1)(+0.05) = +0.20
z[3] = (-1)(+0.15) + (+1)(+0.05) = -0.10
只存储符号: b_K1 = sign(z) = [+1, -1, +1, -1]
存储: 4 bits。这就是我们从残差中保留的全部。
QJL 第 3 步:推理时估算修正项
══════════════════════════════════════════
投影查询(标准 JL,不量化): z_Q = S @ Q
z_Q[0] = (+1)(0.70) + (-1)(0.30) = +0.40
z_Q[1] = (-1)(0.70) + (-1)(0.30) = -1.00
z_Q[2] = (+1)(0.70) + (+1)(0.30) = +1.00
z_Q[3] = (-1)(0.70) + (+1)(0.30) = -0.40
修正项 = (1/m) × Σ(z_Q[i] × b_K1[i])
= (1/4) × [(0.40)(+1) + (-1.00)(-1) + (1.00)(+1) + (-0.40)(-1)]
= (1/4) × [0.40 + 1.00 + 1.00 + 0.40]
= (1/4) × 2.80
= +0.70
QJL 精度:
══════════════════════════════════════════
真实修正值: <Q, e1> = 0.70 × 0.15 + 0.30 × 0.05 = +0.12
QJL 估计: +0.70
误差: |0.70 - 0.12| = 0.58
这个误差很大。但我们只用了 m=4 个投影。
为什么更多投影 = 更小误差:
══════════════════════════════════════════
误差按 1/√m 缩小:
投影数 m 估计误差
────────── ──────────
4 ~0.58
16 ~0.29
64 ~0.15
128 ~0.10
在 m=64(实用设定)时,误差降至 ~0.15。
关键性质:估计器是无偏的
══════════════════════════════════════════
E[correction] = <Q, e_K> (精确等于真实修正值)
每次具体的修正可能偏高或偏低,但在期望上精确正确。
误差是零均值的随机噪声,不是系统偏差。
在 KV cache 的大量 token 上,这些随机误差会平均化。
完整的 TurboQuant 估计器¶
TurboQuant 注意力分数:
══════════════════════════════════════════
TurboQuant score = <Q, K_hat> + QJL correction
────────── ──────────────
有偏但便宜 无偏修正项
期望:
E[score] = <Q, K_hat> + E[correction]
= <Q, K_hat> + <Q, e_K>
= <Q, K_hat + e_K>
= <Q, K>
TurboQuant 在期望上精确恢复了真实的内积。
剩余误差是零均值噪声,随 m 增大而减小。
存储预算(d = 128):
══════════════════════════════════════════
PolarQuant:
128 个坐标 × 3 bits = 384 bits
1 个范数 × 16 bits = 16 bits
小计 = 400 bits
QJL 符号位:
m ≈ 48-64 个符号位 = 48-64 bits
总计每向量: ~448-464 bits
每坐标: 448/128 = 3.5 bits(m=48 时精确)
464/128 = 3.625 bits(m=64 时)
论文报告 3.5 bits 是质量中性点:
(384 + 16 + 48) / 128 = 448 / 128 = 3.5 bits/coord(精确)
性能数据¶
基准测试结果¶
基准测试结果:
══════════════════════════════════════════
TQ 3.5-bit TQ 2.5-bit FP16(全精度)
────────── ────────── ──────────────
LongBench 50.06 49.44 50.06
Needle in Haystack 100.0 99.8 100.0
3.5 bits: 与全精度完全相同
LongBench: 50.06 = 50.06
NIAH: 100.0 = 100.0
2.5 bits: 轻微退化
LongBench: -1.2% 相对差异(49.44 vs 50.06)
NIAH: 500 次测试中漏掉 1 根针
与其他方法的对比¶
与现有 KV Cache 压缩方法对比:
══════════════════════════════════════════
方法 需要训练? 无偏? 压缩比 注意力加速
────── ────────── ────── ───────── ──────────
TurboQuant 否(data-oblivious) 是(QJL) 4.6-6.4× 8×(logits)
KIVI 需要校准数据 否 ~4× ~4×
SnapKV 需要微调 否 2-4× 2-4×
DuQuant 需要校准数据 部分 ~4× ~4×
关于 8 倍加速的说明: 这个 8 倍加速测量的是注意力 logit 计算部分(在 H100 上),而不是端到端推理。完整的推理流程还包括权重加载、FFN 计算、softmax、value 聚合等步骤。对于 prefill-bound 的工作负载,端到端加速通常在 2-4 倍左右。
对 LLM 推理基础设施的影响¶
以 Llama-70B、1M token 上下文、32 GPU 部署为例:
修订后的内存预算(32 GPU,Llama-70B,1M tokens):
══════════════════════════════════════════
FP16 TurboQuant 3.5-bit
───────── ──────────────────
每 GPU 权重 (FSDP) 4.38 GB 4.38 GB
每 GPU KV cache 10.24 GB 2.24 GB
每 GPU 激活值 0.50 GB 0.50 GB
每 GPU 开销 2.00 GB 2.00 GB
───────── ──────────────────
每 GPU 总计 17.12 GB 9.12 GB
剩余空间 (80 GB) 62.88 GB 70.88 GB
批处理容量(能同时处理多少个 1M-token 请求):
══════════════════════════════════════════
固定开销/GPU: 权重 + 系统开销 = 4.38 + 2.00 = 6.38 GB
可用空间: 80 - 6.38 = 73.62 GB
每请求开销:
FP16: KV cache + 激活值 = 10.24 + 0.50 = 10.74 GB
TQ 3.5: KV cache + 激活值 = 2.24 + 0.50 = 2.74 GB
最大批量:
FP16: floor(73.62 / 10.74) = floor(6.85) = 6 请求
TQ 3.5: floor(73.62 / 2.74) = floor(26.87) = 26 请求
提升: 26 / 6 = 4.3× 更多并发请求,相同的 32 GPU 硬件。
GPU 数量需求(Llama-70B,1M tokens,batch=1):
══════════════════════════════════════════
FP16 TQ 3.5-bit
───────── ──────────
权重 140.00 GB 140.00 GB
KV cache 327.68 GB 71.68 GB
───────── ──────────
总计 467.68 GB 211.68 GB
最少 GPU (80 GB) 6 3
其中 KV cache 独占:
FP16: 327.68 / 80 = 4.10 → 5 GPU
TQ: 71.68 / 80 = 0.90 → 1 GPU
在中等上下文长度(128K tokens):
FP16 KV cache: 327.68 × (128K/1M) = 41.94 GB → 1 GPU(紧张)
TQ KV cache: 71.68 × (128K/1M) = 9.18 GB → 1 GPU(轻松)
局限性¶
一般局限¶
- 仅在 8B 模型上测试:论文的实验覆盖 Gemma、Mistral、Llama-3.1-8B,未展示 70B+ 模型的扩展性
- 加速测量范围有限:8 倍加速仅针对注意力 logit 计算,不是端到端推理
- 无官方实现:Google 未发布官方代码,社区存在 PyTorch/Triton 实现
- 未在生产系统部署确认:没有证据表明该方法已在 Google 生产系统中使用
接近 Shannon 极限¶
量化的 Shannon 极限:
══════════════════════════════════════════
信息论给出了量化误差的理论下界:
MSE_min ≥ c(d) × 2^(-2b)
在 b = 3.5 bits 时:
2^(-2 × 3.5) = 2^(-7) = 1/128 = 0.0078
TurboQuant 实现的 MSE ≈ 2.7 × MSE_min
这意味着:
理论上最多还能再提升 log₂(2.7) ≈ 1.4 bits 的等效精度
实际天花板约在 ~2.1 bits/value
差距就是 3.5 bits 和 ~2.1 bits 之间的距离
在 KV Cache 量化这个方向上,低垂的果实已经被摘完了。
总结¶
关键指标:
══════════════════════════════════════════
指标 数值
────────────────── ──────────────────
KV cache 压缩比 4.57×(3.5-bit)到 6.40×(2.5-bit)
注意力 logit 加速 (H100) 8×
精度损失(3.5-bit) 零(多项基准)
精度损失(2.5-bit) -1.2%(LongBench 相对)
需要微调 否
需要校准数据 否
有效比特 ~3.5 bits/value
距 Shannon 极限 ~2.7× 因子
测试的模型 Gemma, Mistral, Llama-3.1-8B
会议 ICLR 2026
核心概念速查¶
| 概念 | 机制 | 关键洞察 |
|---|---|---|
| 异常值问题 | KV 向量中少数维度值极大 | 全局量化精度被异常值主导 |
| 归一化开销 | 按维度 scale 消耗的存储抵消压缩收益 | 低比特场景下 scale 存储本身成为瓶颈 |
| PolarQuant | 随机预处理 + 极坐标变换分散异常值能量 | 消除归一化开销,使统一量化可行 |
| QJL | 1-bit 符号量化 JL 变换修正量化偏差 | 非对称估计器提供无偏修正,零额外存储 |
| TurboQuant | PolarQuant + QJL 组合 | 无偏估计器,无需训练(data-oblivious),接近理论极限 |
| 基础设施影响 | 内存减少 → 并发增加 → GPU 需求降低 | 4.3× 并发提升,GPU 数量减半 |
补充:PolarQuant 的完整数学细节¶
本文正文采用"正交旋转 + 统一标量量化"的简化视角来讲解 PolarQuant 的核心直觉。本节补充 PolarQuant 论文中实际使用的递归极坐标分解算法、角度集中现象、Codebook 构建流程,以及与现有工业方案 NVFP4 的对比。
参考来源:I Spent 31 Hours on the Math Behind TurboQuant So You Don't Have To (Baseten)
以下图片来自 Baseten 文章,用于辅助理解本节内容。
与 NVFP4 的对比:为什么需要新方案¶
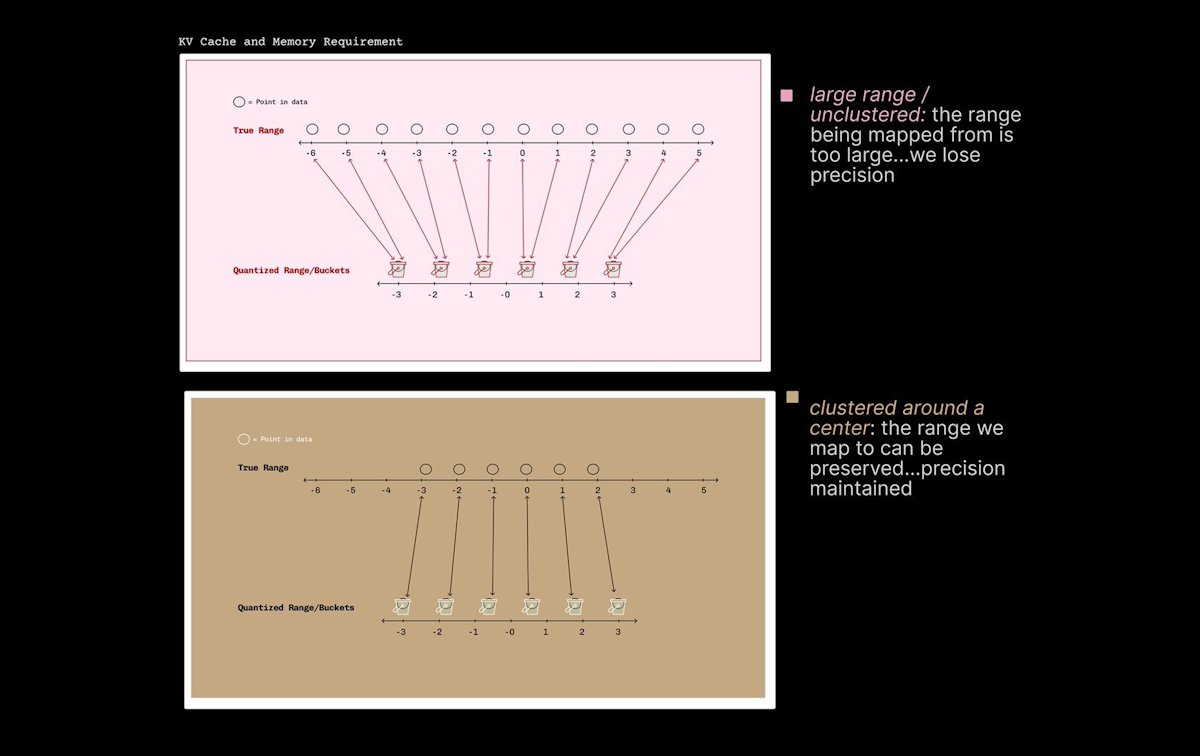
NVIDIA 的 NVFP4 是当前工业界广泛使用的 4-bit 量化方案,采用两层归一化:
NVFP4 量化流程:
══════════════════════════════════════════
1. 全局扫描: 找到整个矩阵的全局最大值
2. 块级最大值: 对每 16 个元素为一组,找组内最大值
3. 归一化: 值 / 组内最大值,scale / 全局最大值
4. 量化: 将归一化后的值映射到最近的 4-bit 桶
5. 反量化: 硬件乘以逆 scale 因子还原
问题:
- 每个 16 元素块需要存储一个 FP16 scale + 一个 zero-point
- 这些归一化常数是纯开销
- 单个异常值会破坏整个块的精度
PolarQuant 的核心优势:
| 特性 | NVFP4 | PolarQuant |
|---|---|---|
| 桶的分布 | 均匀间隔 | 根据已知分布加权 |
| 归一化开销 | 每块存 scale + zero-point | 无开销 |
| 校准需求 | 需要校准数据或在线扫描 | 解析预计算,无需数据 |
| Codebook 设计 | 依赖数据分布 | 仅依赖数学分布(data-oblivious) |
两个关键数学性质¶
PolarQuant 的理论基础建立在多元正态分布的两个性质之上:
性质 1:随机矩阵预处理产生高斯输出
对任意固定向量 \(x\),若 \(S\) 是一个元素独立采样自 \(\mathcal{N}(0, 1)\) 的随机矩阵,则:
输出变为以零为中心、方差等于原始向量长度平方的多元高斯分布——无论原始向量长什么样。
性质 2:高维向量范数的集中性
当向量的每个坐标独立服从标准正态分布时,向量范数服从广义 Gamma 分布:
在高维度下(\(d \gg 1\)),范数紧密集中在 \(\sqrt{d}\) 附近。这意味着预处理后,KV 向量的每个坐标表现得如同来自同一个钟形曲线,为后续的无数据量化奠定了基础。
递归极坐标分解算法¶
PolarQuant 的实际算法不是简单地做标量量化,而是将 \(d\) 维向量递归分解为极坐标表示,然后对角度进行量化:
递归极坐标分解(d=128 为例,log₂(128)=7 层):
══════════════════════════════════════════
输入: 预处理后的 d 维向量 y
r = y.clone()
angles = []
for level in range(n_levels): # 7 层(对于 d=128)
a = r[0::2] # 偶数索引
b = r[1::2] # 奇数索引
level_angles = atan2(b, a)
if level == 0:
level_angles = level_angles mod 2π # 第 1 层:完整 [0, 2π)
# level >= 1: 角度自动落在 [0, π/2](因为半径非负)
new_r = sqrt(a² + b²) # 新的半径
angles.append(level_angles)
r = new_r # 半径作为下一层输入
return angles, r # angles: 各层角度; r: 最终剩余半径
逐层理解:
- 第 1 层:将 128 个原始坐标配成 64 对 \((x_{2j-1}, x_{2j})\),转为 64 个角度 + 64 个半径。原始坐标可为负,角度范围 \([0, 2\pi)\)
- 第 2 层:将 64 个半径配成 32 对,得到 32 个角度 + 32 个半径。半径恒正,角度范围 \([0, \pi/2]\)
- 第 3 层:32 → 16 个角度 + 16 个半径(每个半径概括了 4 维子空间)
- ...
- 第 7 层:2 → 1 个角度 + 1 个半径(每个半径概括了 64 维子空间)
最终:64 + 32 + 16 + 8 + 4 + 2 + 1 = 127 个角度 + 1 个最终半径 = 128 个值(信息无损)。
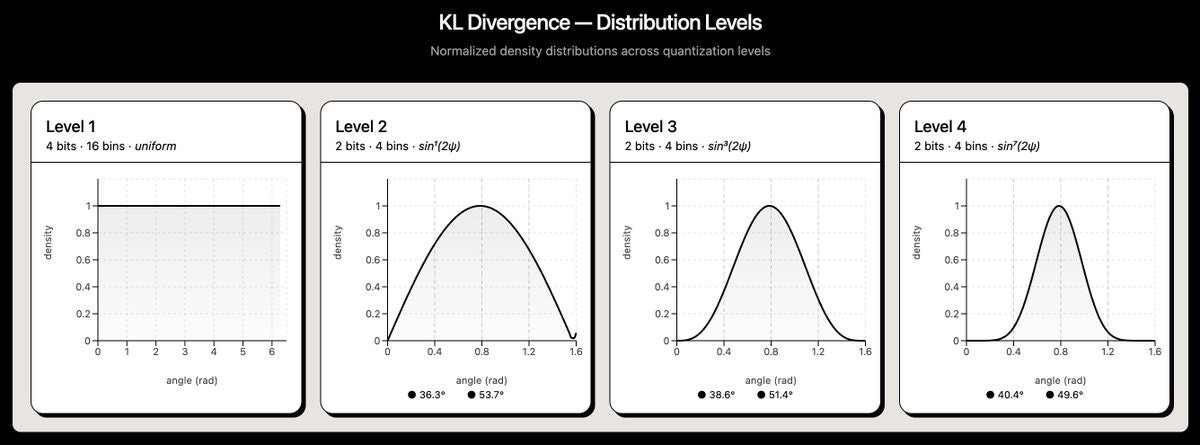
角度集中现象:为什么高层角度几乎不需要比特¶
这是 PolarQuant 最精妙的洞察。第 \(\ell\) 层(\(\ell \geq 2\))角度的概率密度为:
关键性质:
- 期望值:\(E[\Theta] = \pi/4\)(所有层相同)
- 方差:\(\text{Var}(\Theta) = O(1/d)\)(随维度增大而缩小)
直觉理解:第 \(\ell\) 层的角度是 \(\arctan(r_1 / r_2)\),其中 \(r_1\) 和 \(r_2\) 是两个 \(2^{\ell-1}\) 维子空间的范数。由性质 2,高维范数集中在 \(\sqrt{d}\) 附近,所以两个范数的比值趋近 1,\(\arctan(1) = \pi/4\)。
- 2D 范数变化很大 → 角度分布宽
- 8D 范数几乎不变 → 角度紧密集中
- 64D 范数(第 7 层)→ 角度几乎退化为常数 \(\pi/4\),1-bit 即可量化
分层量化策略与 Codebook 构建¶
利用角度集中现象,不同层使用不同的比特数:
分层量化策略(d=128):
══════════════════════════════════════════
层级 角度数 范围 比特/角度 总比特
────── ────── ────────── ───────── ──────
第 1 层 64 [0, 2π) 4 bits 256
第 2 层 32 [0, π/2] 2 bits 64
第 3 层 16 [0, π/2] 2 bits 32
第 4 层 8 [0, π/2] 2 bits 16
剩余半径 8 FP16 16 bits 128
──────
总计 496 bits
对比 FP16: 128 × 16 = 2,048 bits
压缩比: 2,048 / 496 = 4.13×
Codebook 构建三步流程:
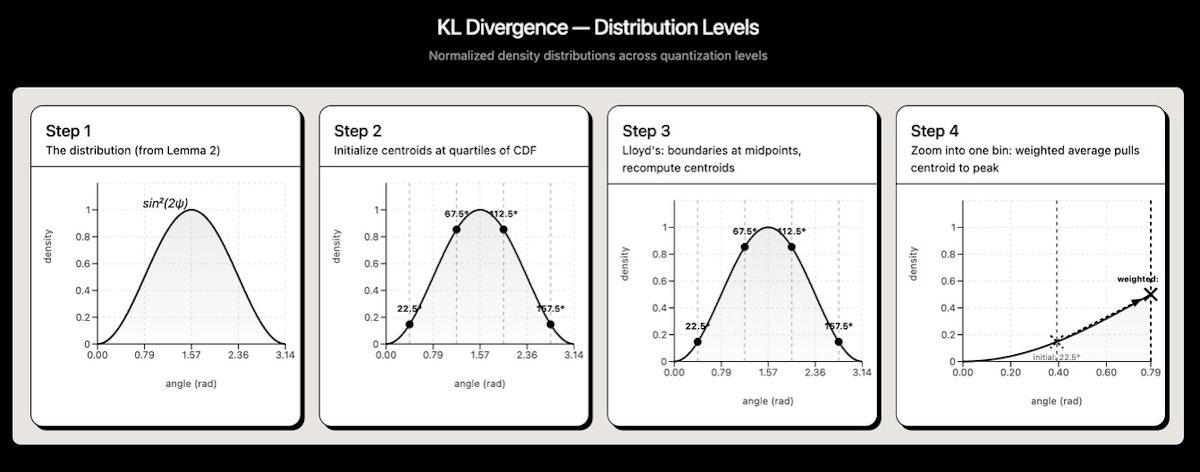
- PDF 生成:利用每层角度的解析分布(上面的 sin 幂公式),在角度范围内采样概率密度
- CDF 分位数映射:将 PDF 转为累积分布,对于 \(n\) 个量化桶,找到累积概率为 \(\frac{i+0.5}{n}\)(\(i = 0, 1, \ldots, n-1\))处对应的角度值作为初始中心点
- Lloyd 算法迭代优化:
- 在相邻中心点之间画边界(取中点)
- 对每个桶,计算概率加权的质心作为新的中心点
- 重复至收敛(移动量 \(< 10^{-7}\))
最终存储每个中心点的 \(\cos\) 和 \(\sin\) 值作为查找表,推理时直接查表重建。
关键优势:整个 Codebook 构建过程只依赖数学分布,不需要任何数据——这就是 PolarQuant "data-oblivious" 的含义。
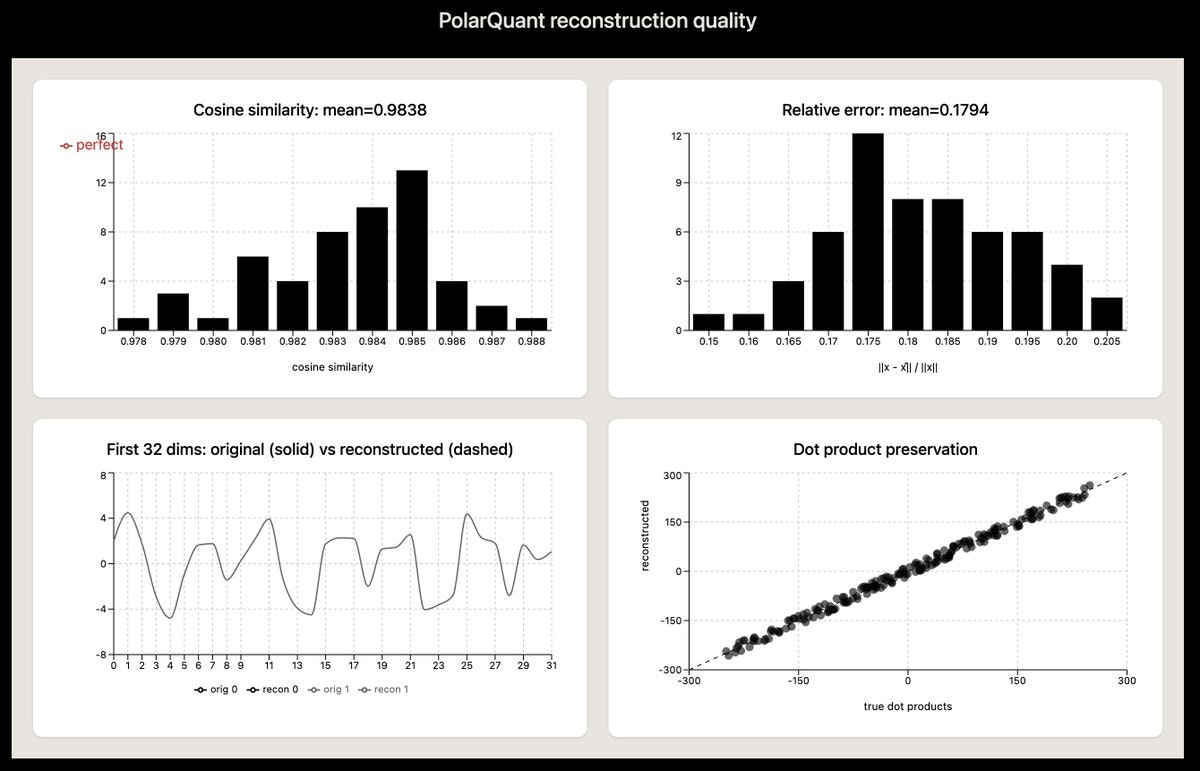
Kernel 性能实测¶
社区实现的自定义 CUDA kernel 的实测性能(相对于 cuBLAS matmul):
Kernel 性能基准:
══════════════════════════════════════════
序列长度 相对 cuBLAS 性能
────────── ──────────────────
< 8K 被 kernel launch 开销主导,无实质差异
8K - 65K cuBLAS 快约 50%
65K - 512K 达到 cuBLAS 的 ~75%
结论: 在长序列场景(>65K tokens)下竞争力较强,
短序列场景仍有优化空间。
References¶
- Darshan Fofadiya — TurboQuant: KV Cache Compression(原文博客)
- A. Zandieh, M. Daliri, M. Hadian, V. Mirrokni. TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate. ICLR 2026.
- I. Han, P. Kacham, A. Karbasi, V. Mirrokni, A. Zandieh. PolarQuant: Quantizing KV Caches with Polar Transformation. AISTATS 2026.
- A. Zandieh, M. Daliri, I. Han. QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead. AAAI 2025.
- Baseten — I Spent 31 Hours on the Math Behind TurboQuant So You Don't Have To
- Johnson-Lindenstrauss Lemma — Wikipedia
- Lloyd-Max Quantization — Wikipedia